# MS-SQL-Server
# equals null
×: = null
√: is null
select name from Customer where referee_id != 2 or referee_id is null
# distinct
eliminate duplications
select distinct author_id as id from Views where author_id = viewer_id order by id
# as
nick name
SELECT column_name AS alias_name
FROM table_name;
2
SELECT column_name(s)
FROM table_name AS alias_name;
2
SELECT name AS n, country AS c
FROM Websites;
2
# order by
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
2
3
# length()
select tweet_id from Tweets where length(content) > 15
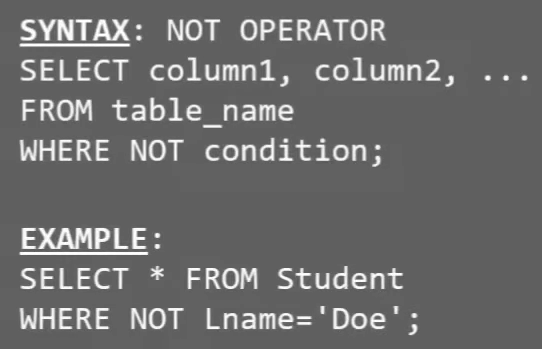
# not
# insert into
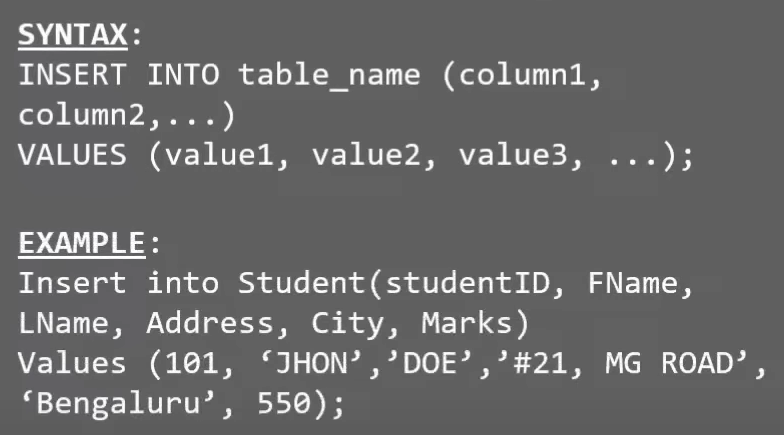
INSERT INTO table_name
VALUES (value1,value2,value3,...);
2
# update
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
2
3
# delete
DELETE FROM table_name
WHERE condition;
2
# Where
# BETWEEN
SELECT column1, column2, ...
FROM table_name
WHERE column BETWEEN value1 AND value2;
2
3
SELECT * FROM access_log
WHERE date BETWEEN '2016-05-10' AND '2016-05-14';
2
# LIKE
SELECT column1, column2, ...
FROM table_name
WHERE column NOT LIKE/LIKE pattern;
2
3
wildcard character:
%
_
[chatlist]
[^chatlist] / [!charlist]
# IN
SELECT column1, column2, ...
FROM table_name
WHERE column IN (value1, value2, ...);
2
3
# AND & OR
SELECT * FROM Websites
WHERE alexa > 15
AND (country='CN' OR country='USA');
2
3
# SQL SELECT TOP
SELECT TOP number|percent column_name(s)
FROM table_name;
2
SELECT TOP 50 PERCENT * FROM Websites;
# Join
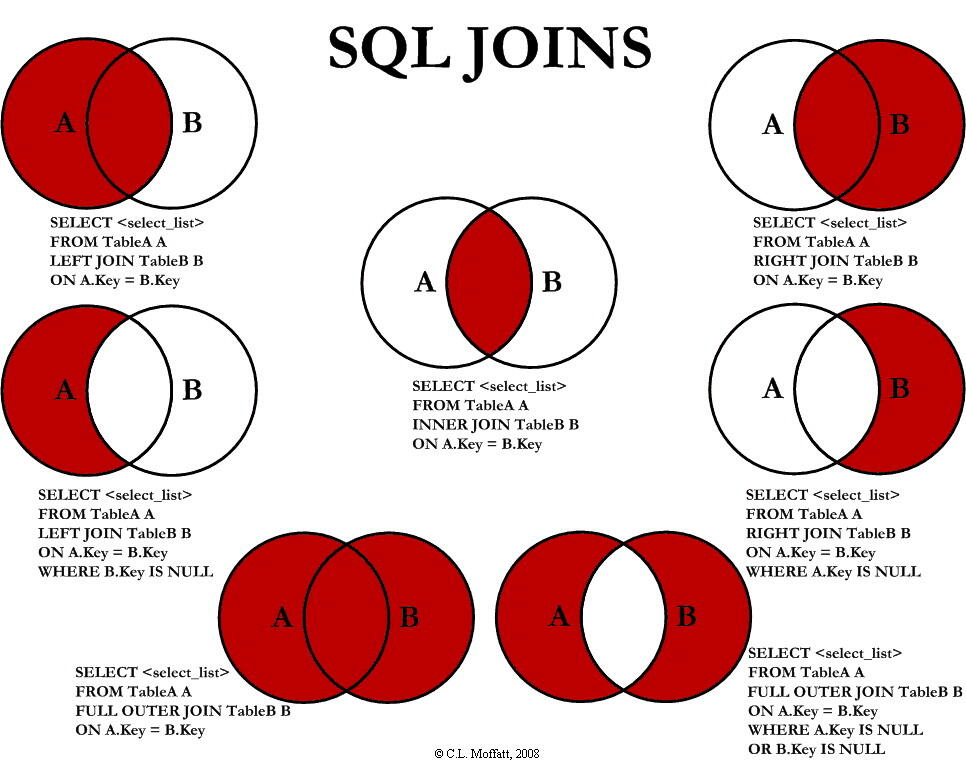
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;
2
3
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
在使用 join 时,on 和 where 条件的区别如下:
- 1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
- 2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
详细内容可以查看:SQL JOIN 中 on 与 where 的区别 (opens new window)
# Inner Join
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
2
3
4
OR
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;
2
3
4
# Left Join
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
2
3
4
OR
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
2
3
4
# Right Join
RIGHT JOIN OR RIGHT OUTER JOIN
# Full Outer Join
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
2
3
4
# Union
union
auto delete duplicates
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
2
3
union all
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
2
3
# Select Into
SELECT *
INTO newtable [IN externaldb]
FROM table1;
2
3
create empty table
SELECT *
INTO newtable
FROM table1
WHERE 1=0;
2
3
4
# Insert into Select
INSERT INTO table2
SELECT * FROM table1;
2
INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;
2
3
4
# Constraints
# SQL CREATE TABLE + CONSTRAINT
CREATE TABLE *table_name*
(
*column_name1 data_type*(*size*) *constraint_name*,
*column_name2 data_type*(*size*) *constraint_name*,
*column_name3 data_type*(*size*) *constraint_name*,
....
);
2
3
4
5
6
7
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
# Not Null
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255) NOT NULL,
Age int
);
2
3
4
5
6
existing table
ALTER TABLE Persons
MODIFY Age int NOT NULL;
2
# Unique
CREATE TABLE Persons
(
P_Id int NOT NULL UNIQUE,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2
3
4
5
6
7
8
命名 UNIQUE 约束,并定义多个列的 UNIQUE 约束
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName)
)
2
3
4
5
6
7
8
9
existing table
Add
ALTER TABLE Persons
ADD UNIQUE (P_Id)
2
ALTER TABLE Persons
ADD CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName)
2
Drop
ALTER TABLE Persons
DROP CONSTRAINT uc_PersonID
2
# Primary Key
# Foreign Key
# Check
CREATE TABLE Persons
(
P_Id int NOT NULL CHECK (P_Id>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2
3
4
5
6
7
8
# Default
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes'
)
2
3
4
5
6
7
8
existing table
Add
ALTER TABLE Persons
ADD CONSTRAINT ab_c DEFAULT 'SANDNES' for City
2
Drop
ALTER TABLE Persons
ALTER COLUMN City DROP DEFAULT
2
# AUTO INCREMENT
SQL Server
CREATE TABLE Persons
(
ID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2
3
4
5
6
7
8
MS-SQL-Server 使用 IDENTITY 关键字来执行 auto-increment 任务。
在上面的实例中,IDENTITY 的开始值是 1,每条新记录递增 1。
要规定 "ID" 列以 10 起始且递增 5,请把 identity 改为 IDENTITY(10,5)。
existing column
ALTER TABLE table_name CHANGE column_name column_name data_type(size) constraint_name AUTO_INCREMENT;
# Alter
add column
ALTER TABLE table_name
ADD column_name datatype
2
delete column
ALTER TABLE table_name
DROP COLUMN column_name
2
change datetype of column
ALTER TABLE table_name
MODIFY COLUMN column_name datatype
2
# SQL Aggregate
# COUNT
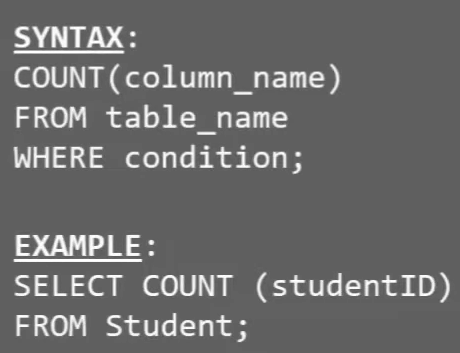
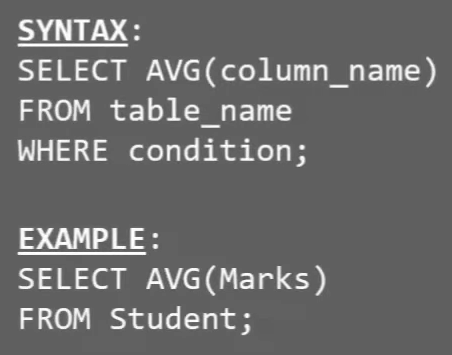
# AVG
# SUM
return total sum of a numeric column

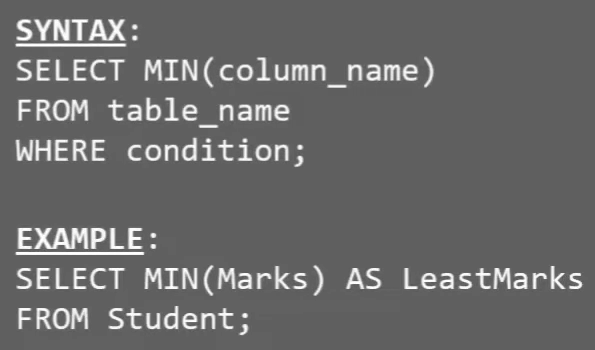
# MIN
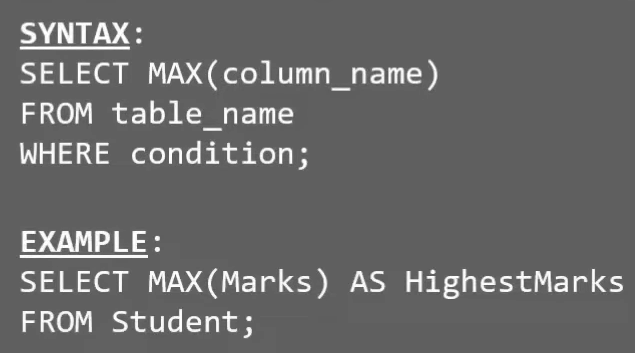
# MAX
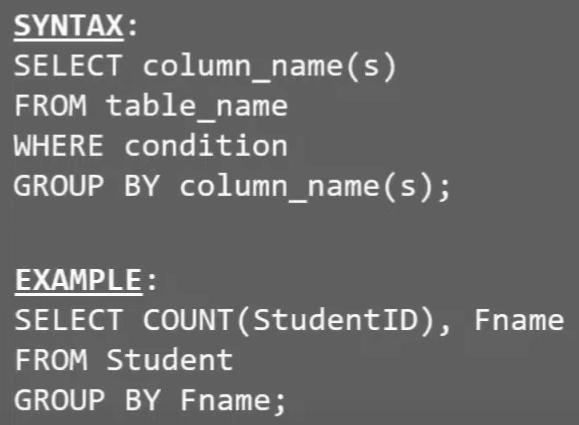
# Group By
# SQL Scalar
# Round()
ROUND() 函数用于把数值字段舍入为指定的小数位数
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;
# UPPER() / LOWER()
SELECT UPPER(name) AS site_title, url FROM Websites;
SELECT LOWER (name) AS site_title, url FROM Websites;
# LEN()
SELECT LENGTH(column_name) FROM table_name;
# SQL Server Date
# GETDATE()
SELECT GETDATE() AS CurrentDateTime
# DATEPART()
DATEPART() 函数用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等等
DATEPART(datepart,date)
SELECT DATEPART(yyyy,OrderDate) AS OrderYear,
DATEPART(mm,OrderDate) AS OrderMonth,
DATEPART(dd,OrderDate) AS OrderDay,
FROM Orders
WHERE OrderId=1
2
3
4
5
| datepart | 缩写 |
|---|---|
| 年 | yy, yyyy |
| 季度 | qq, q |
| 月 | mm, m |
| 年中的日 | dy, y |
| 日 | dd, d |
| 周 | wk, ww |
| 星期 | dw, w |
| 小时 | hh |
| 分钟 | mi, n |
| 秒 | ss, s |
| 毫秒 | ms |
| 微妙 | mcs |
| 纳秒 | ns |
# DATEDIFF()
DATEDIFF function returns the difference between two dates in terms of the specified datepart. The syntax for DATEDIFF is as follows:
DATEDIFF(datepart,startdate,enddate)
- In the problem, the
datepartwill beday(other dateparts can be found here (opens new window)) - The
startdatewill be the previous date - The
enddatewill be the next date - The
DATEDIFF should be 1, i.e., there is 1 day difference between our startdate and enddate.
# DATEADD()
DATEADD function adds a specified number of intervals (such as days, months, or years) to a date and returns a new date. The syntax for DATEADD is as follows:
DATEADD(interval,number,date)
- The
intervalis same as datepart. For our problem, our interval isday. - The
numberis the amount that you want to add to the date. For us, it is1 - The
dateis the previous date and we use it to add thenumberand check with the nextDate.
